José González Oliva
Traceable, reproducible and operable AI backends HARNESS
Architecture Comparison
Strategic approaches to structuring AI systems based on operational complexity and control requirements.
Cloud
Managed services, APIs and agents in the cloud. Faster deployment but higher dependency on external pricing and limited internal control.
OpenClaw
Agent-oriented architecture with routing, plugins and background workflows. Persistent daemon connected to apps and sessions.
NUCLEO
Controlled execution focus. Built-in runtime, decoupled from the model. Explicit boundaries for tools, contracts, and RAG evidence.
Main projects
Controlled local AI runtime
FastAPI backend with explicit request/response contracts, bot/backend services, and per-execution traceability.
Evidence-first document RAG
A RAG flow that checks whether evidence exists before asking the model to answer, with explicit EVIDENCE_FOUND states.
Telegram + observability
Secondary operational channel for testing the backend, with JSONL traces, token metrics, and latency/error status.
Governed AI execution, explained for interviews
This section connects my backend AI work with security, identity, cloud operations and organizational adoption. The point is not to claim production ownership of enterprise IAM/PAM platforms, but to explain the operating model behind NUCLEO: identity-aware, policy-controlled, traceable execution.
PAM/IAM maps naturally to AI agent governance
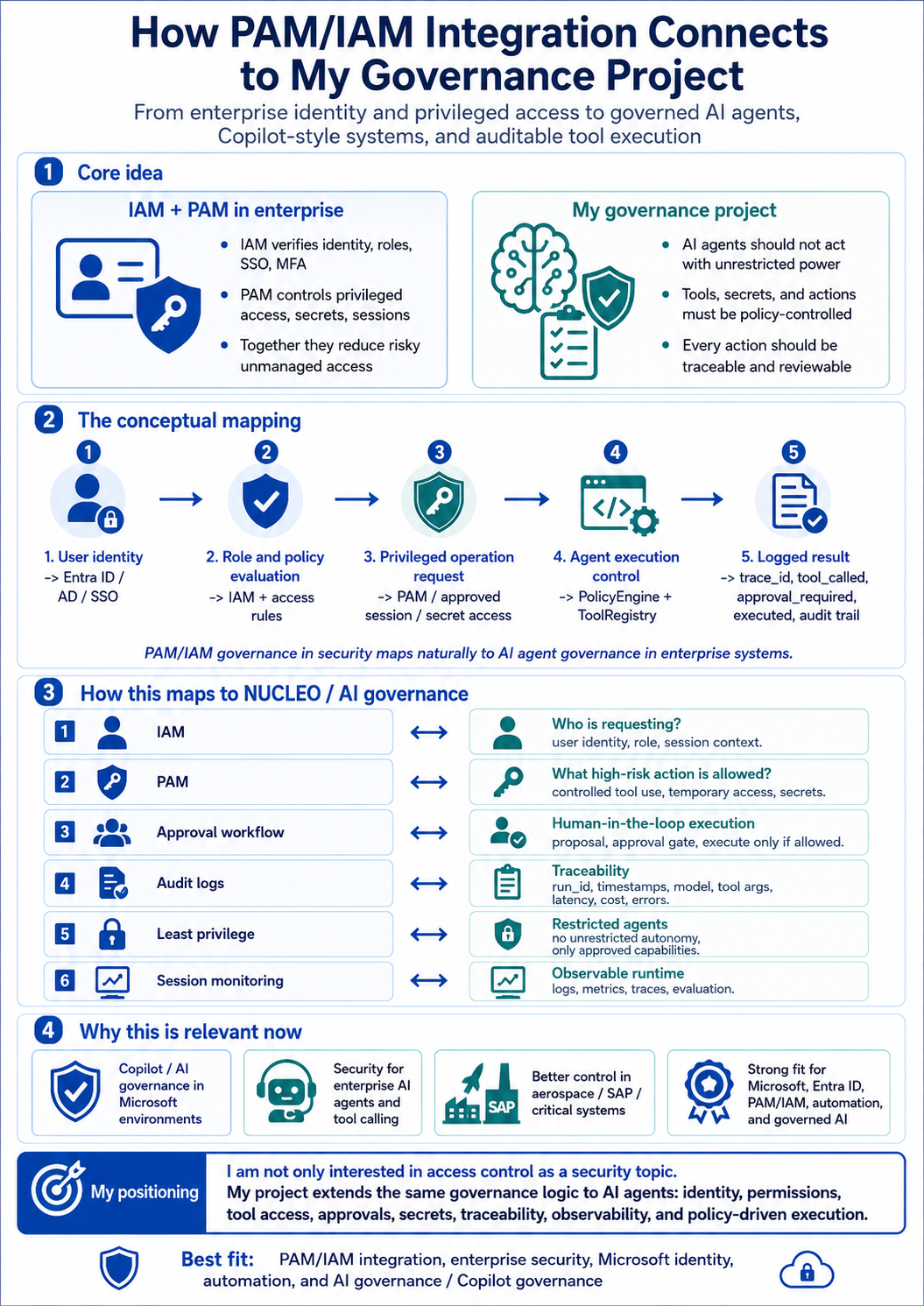
Interview message: the same logic used to control human and service access also applies to AI agents. A model should not call tools, secrets or business actions without identity context, policy checks, approvals and audit records.
- IAM answers who is requesting and under which role.
- PAM controls high-risk actions, privileged sessions and secret access.
- NUCLEO applies the same pattern to agent execution: request, policy, tool contract, approval gate, trace.
Why my profile fits PAM/IAM integration conversations
.png)
Interview message: I am not positioning myself as a pure CyberArk product specialist. The fit is integration and governance: enterprise systems, Microsoft identity, automation, SAP context and auditable AI or Copilot-style access.
- IAM verifies identity, roles, SSO and MFA.
- PAM grants temporary elevated access and monitors critical actions.
- My AI governance work extends that logic to tool permissions, traces and approval flows.
AI literacy is not the same as AI culture

Interview message: teaching prompts is useful, but it is not a full AI strategy. The harder problem is redesigning workflows, deciding what should be automated, measuring outcomes and changing how teams operate.
- AI literacy improves existing tasks.
- AI culture questions whether the task should exist in its current form.
- My work focuses on operational systems: workflows, controls, evaluation and measurable change.
Backend is the control room behind cloud and AI systems

Interview message: backend engineering is the control layer that makes cloud and AI systems observable, secure and recoverable. This connects directly with my focus on FastAPI runtimes, traces, provider adapters and controlled tool execution.
- APIs, service logic and integrations define the operating boundary.
- Identity, secrets, logs, health checks and observability keep systems controllable.
- The same backend mindset supports AI agents, Copilot-style tools and local/hybrid LLM runtimes.
Execution metrics
Every AI execution should leave an inspection record. The example below is synthetic and shows how the backend can record model, retrieval status, tokens, latency and result status.
{
"trace_id": "trc_public_demo_ok_001",
"source": "telegram",
"provider": "ollama",
"model": "local-model-demo",
"retrieval_status": "evidence_found",
"tokens_input": 1210,
"tokens_output": 286,
"latency_ms": 1730,
"output_tokens_per_second": 19.4,
"status": "ok"
}
Technical stack
Backend
Python, FastAPI, HTTP contracts, payload validation, layered services and local APIs.
AI / LLM
Document RAG, local models, provider adapters, prompt policies and model output checks.
Data
JSON contracts, synthetic traces, retrieval metadata, document chunks and auditable response records.
Operations
Latency, token counts, error states, JSON/JSONL logs and deterministic evals for drift detection.
Integrations
Static web pages, Telegram bots and backend APIs used to test AI flows through real channels.
Current limitations
- warning Advanced prototype; not a production system.
- warning Local experimental backend, not a deployment-ready platform yet.
- warning Observability is local and JSON-based, not centralized production monitoring.
- warning No public validation for high concurrency.